Aggregate Function Networks: Architecture and Theory
Although we are best known for the PAPERS network
hardware, believe it or not, we're compiler folk. In fact,
since the early 1980s we have been doing fine-grain compiler
code scheduling... which is how we came to be interested in
hardware barrier synchronization and, more
recently, how we created the concept of aggregate
function communication.
Barrier synchronization is an N-way operation in which no processor is
allowed to execute beyond the barrier until all N processors have
arrived. It was in 1987 that we noticed that barriers are the key to
most forms of static scheduling, including support of SIMD and VLIW
execution modes.
We were not the first to recognize that, in hardware terms, barrier
synchronization is essentially an AND gate. However, we went much
further, creating the concept of arbitrary groups of processors
specified by "barrier bit masks," and defining classes of barrier
mechanisms based on how barriers affecting disjoint processor groups
were handled. Most of this happened by 1990 ICPP (where our barrier
papers created quite a stir), but it was late in 1993 that we finally
discovered a method for efficiently building the most general type of
barrier mechanism.
This new barrier mechanism requires a very special type of
communication mechanism for collecting and transmitting barrier
masks. When we built it, in February 1994, it didn't take long for us
to realize that this communication was arguably even more significant
than the fast barrier hardware it supported. Why? Because in a single
operation, each processor could simultaneously sample data from all
processors (originally, just one bit from each processor)... and this
ability to sample global state does marvelous things.
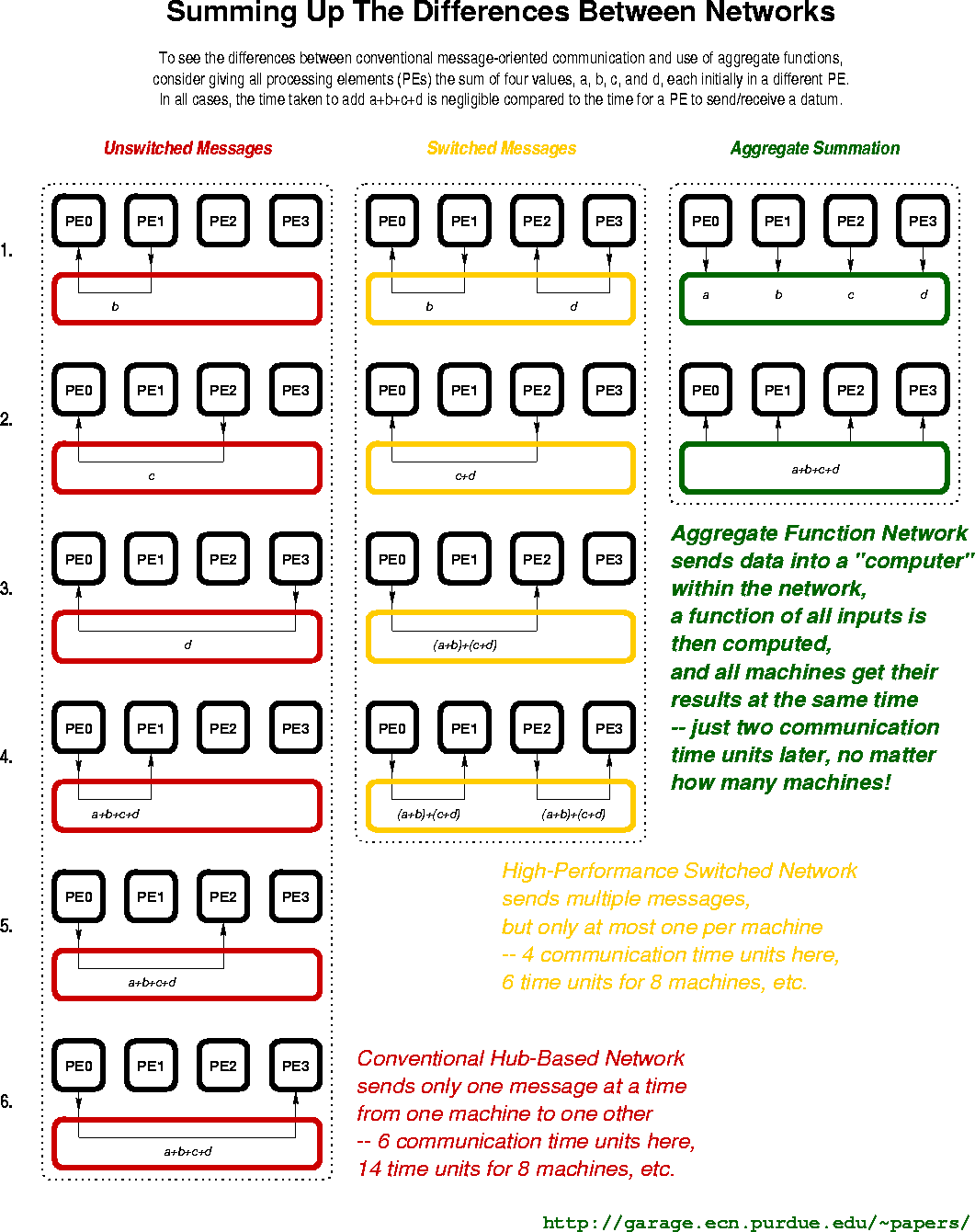
Thus was born the aggregate function communication model, in which we
allow each processor to specify the function it wants computed from
the data posted by all N processors. Basic aggregate function
communication operations range from multibroadcasts, reductions, and
scans to systolic-style operations like counting the number of
processors voting "true."
The software and hardware designs for Aggregate Function Networks
have been placed in the public domain. Please see the following
web pages:
Barrier/Aggregate Function Architecture
-
Aggregate Networks Using Network Memory
(.ps)
-
R. Hoare and H. Dietz, "A Case for Aggregate Networks,"
Proceedings of the merged 12th International Parallel
Processing Symposium and 9th Symposium on Parallel and
Distributed Processing (IPPS/SPDP '98), pp. 162-166, Orlando,
FL, March, 1998. This paper discusses some fancier types of
aggregate functions that can be implemented using memory
within the network.
-
Single-Chip Aggregate Function Clusters
(.ps)
-
S. Kim, R. Hoare, and H. Dietz, "VLIW Across Multiple
Superscalar Processors On A Single-Chip: A Smart Compiler and
A Smart Machine," Proceedings of International Conference on
Parallel Architectures and Compilation Techniques (PACT '97),
pp. 166-175, San Francisco, CA, November, 1997.
-
Bitwise Aggregate Networks
(.ps)
-
R. Hoare, H. Dietz, T. Mattox, and S. Kim, "Bitwise Aggregate
Networks," Proceedings of The Eighth IEEE Symposium on
Parallel and Distributed Processing (SPDP '96), New Orleans,
LA, October 1996. This paper describes some of the marvelous
things that can be done using only a simple bitwise logic
function to implement all aggregate functions. It is very
close to systolic architecture....
-
Modularly Scalable Static Barriers
(.ps)
-
H. G. Dietz, R. Hoare, and T. Mattox, "A Fine-Grain Parallel
Architecture Based On Barrier Synchronization," Proceedings of the
International Conference on Parallel Processing, pp. 247-250,
August 1996.
-
The New Dynamic Barrier Mechanism
(.html,
.ps)
-
W. E. Cohen, H. G. Dietz, and J. B. Sponaugle,
Dynamic Barrier Architecture For Multi-Mode Fine-Grain Parallelism
Using Conventional Processors;
Part I: Barrier Architecture,
Purdue University School of Electrical Engineering,
Technical Report TR-EE 94-9, March 1994.
-
The First Barrier MIMD Paper
(PDF)
-
Henry G. Dietz and Thomas Schwederski, Extending Static
Synchronization Beyond SIMD and VLIW, Purdue University School of
Electrical Engineering, Technical Report TR-EE 88-25, June 1988. For
a brief history of this paper, click here).
Theoretical Foundations
(How To Use Barriers/Aggregate Functions)
-
Timing Analysis and Code Scheduling
(.html,
.ps)
-
H. G. Dietz, M. T. O'Keefe, and A. Zaafrani,
"An Introduction to Static Scheduling for MIMD Architectures,"
Proceedings of the Third Workshop on Programming Languages and
Compilers for Parallel Computing, pp. 1-26, Irvine, California,
August 1990. (A revised version appears in
Advances in Languages and Compilers for Parallel Processing,
edited by A. Nicolau, D. Gelernter, T. Gross, and D. Padua, The MIT
Press, Cambridge, Massachusetts, 1991, pp. 425-444.)
-
MIMD/SIMD/VLIW Mode Emulation
(.html,
.ps)
-
W. E. Cohen, H. G. Dietz, and J. B. Sponaugle,
Dynamic Barrier Architecture For Multi-Mode Fine-Grain Parallelism
Using Conventional Processors;
Part II: Mode Emulation,
Purdue University School of Electrical Engineering,
Technical Report TR-EE 94-10, March 1994.
-
SIMD/MIMD Mode-Independent Parallel Languages
(.html)
-
Michael J. Phillip, Unification of Synchronous and Asynchronous
Models for Parallel Programming Languages, MS Thesis, School of
Electrical Engineering, Purdue University, May 1989.
 The only thing set in stone is our name.
The only thing set in stone is our name.