
In this project, your team is going to build a pipelined implementation of TACKY. Although TACKY isn't a very wide VLIW, it is a VLIW and your pipelined implementation is expected to be able to complete as many as two packed instructions every clock cycle -- yes, an IPC of 2.
Remember EE380? Not really? That's ok... just play along anyway. Back in EE380, we followed a rather neat plan in the textbook that basically recommended that a pipelined design could best be created by initially designing a slow single-cycle implementation. The function units, data paths, and control signals defined for the single-cycle implementation could then be used (with only minor modifications) in the pipelined version. It was mostly just a matter of carving the single-cycle design into appropriate pipeline stages... probably about 5 of them. Well, now is the time we see if that approach really works....
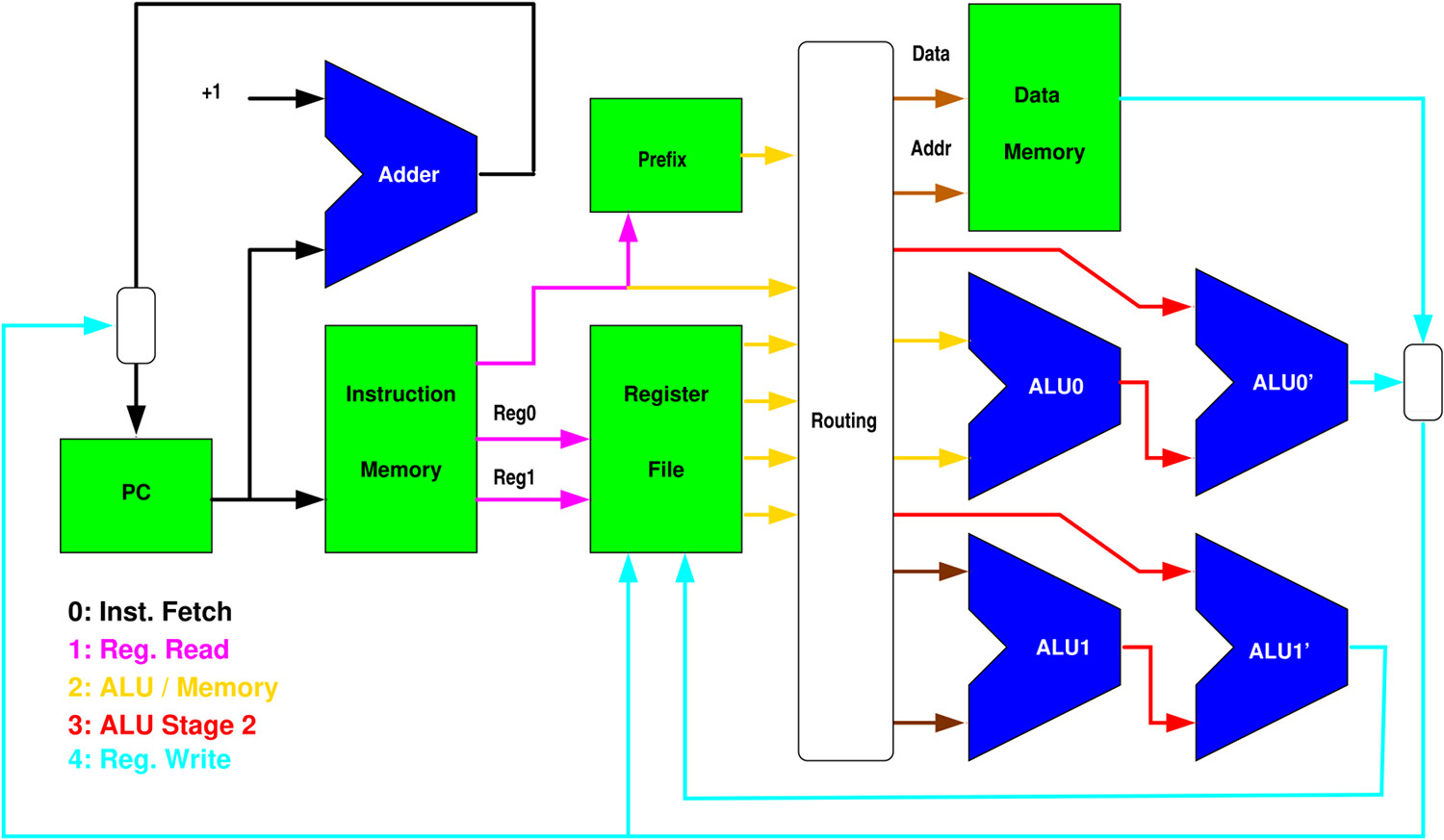
I don't suggest that you should take the following diagram too literally.... However, here's a rough diagram showing one way to start thinking about a single-cycle implementation that you can then pipeline:
We have been discussing most of the issues in class. I'm not going to go through everything here, but key ideas include:
Well, that wasn't so bad now, was it? Well, of course not... because that's not what you have to do. You have to make a pipelined design; that was just a crude approximation to a single-cycle design with some comments about how to pipeline it.
One of the first steps in making a pipelined implementation is figuring-out how many stages there should be and what belongs in each.
Although we are not forcing you to do any timing analysis, as stated above, you should make reasonable assumptions about how much can be done in one clock cycle. It is fairly obvious that the memories (including the register file and even the lookup table in reciprocal) will take a little while to access, and we all know ALUs are notoriously slow -- although we'll allow the ALU to do any integer or simple floating-point operation in just one clock period. Thus, we'd expect a stage for each of those things along any circuit path. The most natural result here is a pipeline with 5 stages (you really shouldn't be ending-up with fewer than 4 stages).
As we have been discussing in class, one of the most useful concepts in creating hardware (or parallel software) is owner computes: the idea that each register/memory should be written into by only one entity, its owner, and that entity should also compute the value that will be written. Thus, a pipeline doesn't really look at all sequential. Instead, a pipeline is a set of independent, parallel-executing, entities that communicate by the owner of each register updating the register value which is read by one or more other entities. For example, the buffer at the end of the instruction fetch stage (let's call this stage 0) will certainly include a register that holds the register numbers (Reg0 and Reg1), and this register is owned and written by stage 0. Of course, the register number used as a destination is potentially needed until the very last stage (where the register write is done), but it doesn't stay in one place: each stage will have its own register for that. For example, stage one might own "Reg11" and normally will set it to the value read from "Reg10". Keep in mind that the PC has more than one potential source for its next value -- but the Verilog always block that logically owns the PC is the only thing that should write a new value into it.
Ok, so each stage is probably its own always block. However, computing complex formulas also can be isolated into little always, or even combinatorial assign, blocks that aren't pipeline stages per se; they are parallel-execting hardware units that exist for the sole purpose of owning that computation's result. For example, you might find it easier to have a separate block that owns and computes the interlock condition that would prevent the instruction fetch and register read stages (stages 0 and 1) from advancing when there is a dependence on an instruction further in the pipeline.
Not too bad, right? Well, here are a few more things to think about:
a: a2r $r2, li $r3 ; r2=r0, r3=mem[r1] b: add $r3, mul $r2 ; r0=r0+r3, r1=r1*r2 c: sub $r1, div $r0 ; r0=r0-r1, r1=r1/r0
Let's be completely clear about what I expect: your submission should be a viable four-or-more-stage pipelined Verilog implementation of the TACKY instruction set. The significant design decisions made should also be discussed in your Implementor's Notes.
Assignment 2 was scary, but that was mostly because you had never done something like this before -- now you have. For this project, you are allowed to reuse any pieces from the Assignment 2 solutions that you, or any of your Assignment 3 teammates. helped create. You also may use any materials I give you, which includes a sample solution for Assignment 2; a cleaned-up version of what I reviewed in class Friday, October 19, is posted here, but note that you really want to put appropriate stuff in instruction and data memory rather than just intialize a few words using assignments. Perhaps most importantly, you also are free to not use any of those things; in other words, you can combine any of those materials and make changes as your Assignment 3 team sees fit. For example, if you don't like the way instruction fields are encoded, feel free to re-write the AIK assembler (but make sure your Implementor's Notes documents how instructions are encoded and why).
In general, you are not allowed to use anything from another Assignment 3 team nor from an Assignment 2 team that none of your Assignment 3 team members were on. You can use things done by any of your Assignment 3 team members, including things their teams did on Assignment 2, and things provided as part of this assignment.
As discussed in class, Verilog code that specifies memory accesses somewhat carelessly is very likely to result in a bigger circuit than if we carefully factored things into modules and created single instances of those modules. For example, a Verilog compiler might fail to map Data Memory into a dedicated memory block within an FPGA, instead constructing a memory using thousands of logic cells. Using an instance of a memory module designed to comply with the FPGA-maker's guidelines (e.g., this dual-port RAM with a Single Clock from ALTERA, which is this Verilog code) ensures that the vendor's Verilog toolchain will correctly infer use of the intended hardware modules inside the FPGA. Of course, in this class we are not rendering designs into physical circuits, so these issues of complexity (and timing analysis) are neither obvious nor critical... but you should always be aware of the potential hardware complexity you risk introducing by using a specification style that doesn't explicitly factor-out the desired modules.
Again, the test coverage plan and testbench from Assignment 2 are probably very close to what you want. However, you do need to seriously think about coverage again. Why? You are not testing the same Verilog code, so there may be some paths that didn't exist before -- and they might not be covered with a testbench that covered your old version.
Just to be clear, I do not expect you to incorporate any design for testability features in your Verilog design.
The recommended due date is Monday, April 1, 2019. By that time, you should definitely have at least submitted something that includes the assembler specification (tacky.aik), and Implementor's Notes including an overview of the structure of your intended design. That overview could be in the form of a diagram, or it could be a list of top-level modules, but it is important in that it ensures you are on the right track. Final submissions will be accepted up to just before class on Friday, April 5, 2019.
Note that you can ensure that you get at least half credit for this project by simply submitting a tar of an "implementor's notes" document explaining that your project doesn't work because you have not done it yet. Given that, perhaps you should start by immediately making and submitting your implementor's notes document? (I would!)
For each project, you will be submitting a tarball (i.e., a file with the name ending in .tar or .tgz) that contains all things relevant to your work on the project. Minimally, each project tarball includes the source code for the project and a semi-formal "implementors notes" document as a PDF named notes.pdf. It also may include test cases, sample output, a make file, etc., but should not include any files that are built by your Makefile (e.g., no binary executables). Be sure to make it obvious which files are which; for example, if the Verilog source file isn't tacky.v or the AIK file isn't tacky.aik, you should be saying where these things are in your implementor's notes.
Submit your tarball below. The file can be either an ordinary .tar file created using tar cvf file.tar yourprojectfiles or a compressed .tgz file file created using tar zcvf file.tgz yourprojectfiles. Be careful about using * as a shorthand in listing yourprojectfiles on the command line, because if the output tar file is listed in the expansion, the result can be an infinite file (which is not ok).