
Welcome to the home of FNN documents and software! Since the press releases on our clusters KLAT2 and KASY0, which have Flat Neighborhood Networks, many of you have been asking us for more information, access to the GA (genetic search algorithm) we developed to design FNNs, etc. This is where everything will be posted....
A FNN is a network that guarantees single-switch latency and full link bandwidth per PE (Processing Element) pair on a wide variety of parallel communication patterns. It does so using a flat topology of PEs connected to switches, where each switch forms a neighborhood of tightly coupled PEs. The switches are nominally connected only to PEs and not to each other. They key is that each PE in a FNN is connected to several switches, and is thus a member of several neighborhoods. The overall effect is that PE pairs can communicate with single switch latency and full link bandwidth across the entire machine, even though each individual neighborhood does not encompass the entire machine.
There are two classes of FNNs based on which pairs of PEs have guaranteed latency and bandwidth:
Publications on Sparse FNNs (SFNN) have their own page. The following publications discuss what we now call Universal FNNs:
The following form can be used to submit design parameters to a simplified version of the FNN Design GA (Genetic search Algorithm) that uses a CGI interface. This CGI is a somewhat improved version of our original FNN design CGI; it creates Universal FNN designs very quickly, so it's easy to play with different parameters. We hope to be posting software tools for Sparse FNN design in the near future....
In case you are wondering where the 96, 48, 3 parameters came from, they are the parameters that generate the network design used in Bunyip, from the Australian National University, Canberra. Although our KLAT2 was clearly the first machine designed to use a FNN, our Australian friends just happened to build a network that is a universal FNN at about the same time the we built ours. Thanks to our GA, KLAT2's network design offers substantially higher bandwidths at a lower cost (e.g., Bunyip's bisection bandwidth could be much higher -- try 96, 32, 4), but both machines clearly demonstrate the superior price/performance of FNNs. Incidentally, the Bunyip folks also are using SWAR technology; but they are hand-coding SSE while we've been using a variety of tools with 3DNow!. Small world, eh?
If you're just looking for a brief overview of the Universal FNN technology, read on. There is a separate page for the Sparse FNN technology.
One would think (well, we did ;-) that the latest round of Gb/s network hardware would have made the design of a high-bandwidth cluster network a trivial exercise. However, that isn't the case when the prices are considered:
In summary, the cost of the "obvious" Gb/s network for KLAT2's 66 single-processor nodes was OVER 30 TIMES the cost of the network we built for KLAT2. In fact, to match KLAT2's bisection bandwidth, a network built using Gb/s hardware would have cost even more. Gigabit Ethernet is getting cheaper, but obvious topologies just are not competitive with FNN performance. So, if you've got tons of money that you have to spend immediately, you can impress your friends by buying expensive custom network hardware that can use an obvious topology and still be competitive with FNN performance. Otherwise, read on.... ;-)
When no solution seems to work, it is time to rephrase the problem. We wanted to have the minimum possible latency between any pair of PCs. Clearly, for KLAT2's 66 nodes, you couldn't put 65 NICs in each machine to implement a direct connection... the next best thing would be to have just one switch delay between any two PCs. The problem then becomes that a 66-way switch that can handle communication at full wire-speed is not cheap.
In Fall 2002, you can buy a wire-speed 48-way 100Mb/s switch for about $800. When KLAT2 was built, it was $500 for 32 ports. If we ignore KLAT2's two "hot spare" processors, we could use 32 dual-processor PCs and channel bonding of multiple NICs (http://www.beowulf.org/). However, most dual-processor PCs have memory bandwidth problems and, even if we wanted to adopt that solution, dual-Athlon PCs are not yet widely available.
The "Flat Neighborhood" network topology came from the realization that it was sufficient to share at least one switch with each PC -- all PCs do not have to share the same switch. A switch defines a local network neighborhood, or subnet. If a PC has several NICs, it can belong to several neighborhoods. For two PCs to communicate directly, they simply use NICs that are in a neighborhood that the two PCs have in common. Coincidentally, this flat, interleaved, arrangement of the switches results in spectacular bisection bandwidth -- approaching the same bisection bandwidth that we would have gotten if we had wire-speed switches that were wide enough to span the entire cluster! We even get the benefit that, because four NICs are available for simultaneous use in each PC, we bypass some of the I/O serialization that using IP would imply with a single Gb/s NIC (or channel-bonded set of NICs) under Linux.
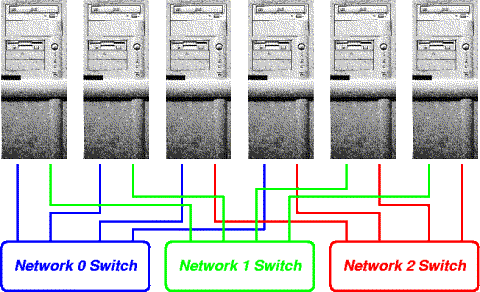
The above example shows how one could construct a FNN for 6 PCs using just two NICs/PC and three 4-port switches. Note that every PC has at least one single-switch-latency path to every other PC; some PC pairs have more than one such path.
Unfortunately, Flat Neighborhood Networks introduce several interesting new problems. These problems are:
Well, those are not easy problems to solve, but we managed to solve all but the last within a week or so. The last one is a pain, which translates to "we are writing the paper on it." We will post more details, including the GA, soon....

As you can see above, KLAT2 is large enough that none of the network design, construction, and routing issues are trivial. In fact, we ran the GA on Odie -- a cluster of four 600MHz Athlons that we built last year. However, here's the good news:
![]() The only thing set in stone is our name.
The only thing set in stone is our name.