There's a silly little "game" -- really a simulation -- called Conway's Game of Life. Basically, it is a cellular automaton that simulates how colonies of cells grow and die over time. The simulated world consists of a simple 2D rectangular array, each element of which can be either live (1) or dead (0). At each timestep, what happens at each point in the array depends on what is in that point and its 8 neighbors:
The "game" aspect of this is the setting of the initial pattern. Then one simply watches how the pattern evolves over many timesteps.
You're going to make it do timesteps really fast by dividing the world into rectangular chunks that can evolve in parallel using MPI to communicate between the pieces.
I know Life seems like a really dumb computation, but parallelizing it actually is a problem worth thinking about. Why? Because doing it the wrong way causes a lot of performance issues. Think of it this way:
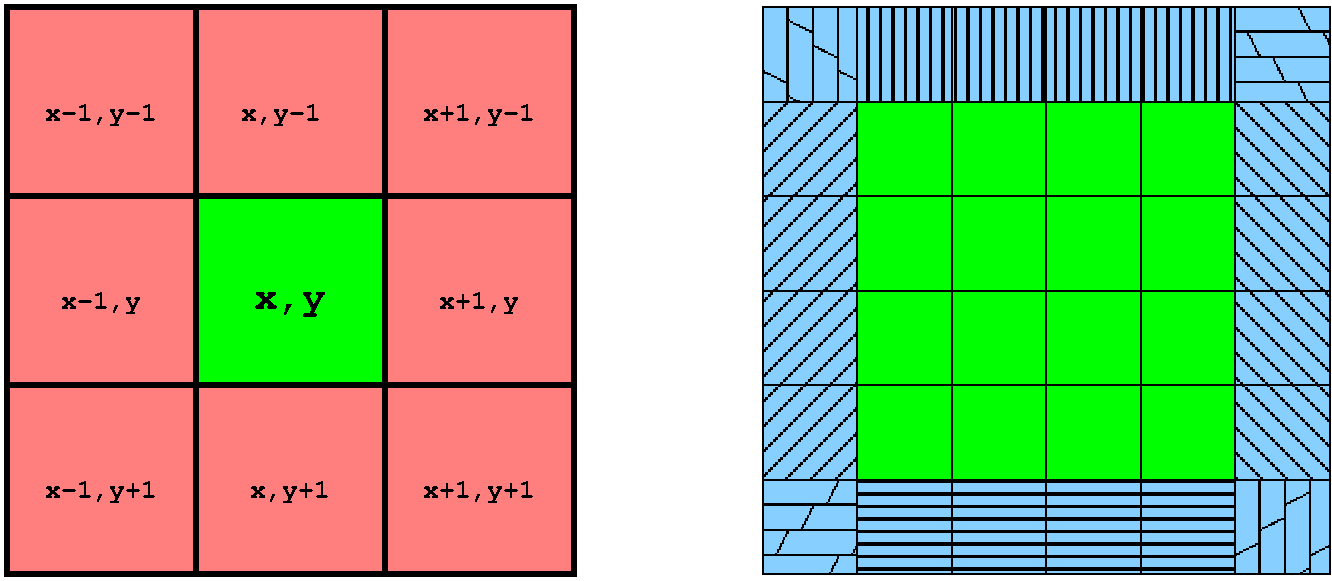
For each x,y position (shown in green), the values of 8 neighbors must be examined (shown in red). If each cell is placed on a processor, this would mean that each processor would have to exchange data with 8 other processors just to make one decision. Yuck! We'd spend all our time communicating. This is precisely the same kind of problem you run into with things like PDE solvers... except I don't have to try to explain PDE solvers to you, which is probably better for all of us. ;-)
The answer is to give each processor a larger block (shown in green), each surrounded by what is commonly called a fake zone (shown in blue). You'll want the blocks to be bigger than the 16-cell one shown here, but hopefully this image gets the idea across. The fake zone essentially implements communication buffers around the block that is assigned to each processor. Note that two of the "communication buffers" in the fake zone have their elements strided such that they cannot be directly used as buffers for MPI messaging... but the other six can be. In any case, the fake zone serves two purposes:
In this way, the number of communications is still eight exchanges (sixteen messages), but the number of computations each processor gets to perform per set of communications increases in proportion to the square of the amount of data transmitted. That's cool. It means communication overhead can be become trivially small if we can have a big enough block in each processor.
In case you have not guessed, this isn't just for Conway's Game of Life -- the exact same self similar fake zone approach is widely used in efficiently parallelizing all sorts of algorithms that require data from neighboring processors.
You're going to write C + MPI code to implement Life across 16 processors. Why 16? Because that allows you to carve the initial array into pieces that are each 1/4 the full x and y dimensions. All the test cases I'll use will have x and y dimensions both multiples of 4. It's also a modest enough number to work well on anything.
You'll use MPI message passing to do all the communications... but it is up to you to decide which of the messaging mechanisms you will use (for example, blocking vs. non-blocking). Depending on how you decide to perform the messaging, it is also worth noting that it would be easy to use the message source info to know where the data in the message just read belongs. Similarly, using the tag field to say which timestep the data belongs to is not a bad idea (although if you do that, you should probably just use the low bits of the timestep as the tag, because your program can be asked to do huge numbers of timesteps).
To get you started, life.c is a little C program I wrote to implement reading-in a P1 bit image file of the inital state (on stdin), iterating for a given number of iterations, and then outputting the final state as a P1 image (on stdout). Functionally, it is what your code should do... except for the fact that it isn't parallel. Here's a tiny test input image:

Well, actually, that's not quite right. First off, most browsers will do some smoothing to scale-up the image, and that blurryness isn't in the binary file. In fact, the input image needs to be an ASCII PBM file (Portable Bit Map file type P1), such as lifetest.pbm. You can easily make your own test images using gimp and saving a .pbm with the ASCII option selected. Obviously, the input image can be much bigger than the above, and bigger ones will usually give greater speedup because of the scaling of communication overhead as mentioned earlier.
You'll find plenty of more interesting starting patterns on the WWW... along with source code for programs doing this sort of thing. Feel free to use the patterns, but not other people's source code. Most of them are treating the arrays as 1 bit per pixel anyway, which I'm explicitly telling you not to do. (Yes, treating this stuff as bits is way more efficient... but this is a course project, not trying to be the most efficient implementation of Life.)
You will be submitting source code, a make file, and a simple HTML-formatted "implementor's notes" document called a1.html, which should explicitly describe how and why you do the message passing as you do (i.e., why did you pick blocking or non-blocking). Please arrange your make file so that the executable file, which should be called a1, is compiled when one simply types make. All of the things needed should be packed into a single tar file for submission by a command like tar -zcvf a1.tgz files -- and that tar is all you submit. Do not include executable files, or other things that can be generated by make, in the tar you submit.
For full consideration, your project should be submitted no later than February 26, 2015. Submit your project tar file here:
 Cluster/Multi-Core Computing
Cluster/Multi-Core Computing