We've talked a lot about various global optimizations, and I certainly want you to build some, but we're running out of time! So, we're going to keep this project simple....
Starting with your (or my sample solution TGZ file) basic block parallelizer, you're now going to add code straightening. What does that mean? Well, even though it's pretty simple as global optimization goes, it means that you've actually got quite a bit to do.
The first step is to build the control flow graph. There will only be one function in your input (I promise), and it is entered at the top, but you'll need to figure-out the control flow from all the SEL and LAB tuples. Each basic block has at most two successors. A SEL tuple ending a block explicitly specifies the successor(s), but falling into a LAB without passing through a SEL also creates a control flow entry to the LAB.
I strongly recommend that you think of the flow graph as a separate data structure in which each node represents an original basic block. Each node contains a sequence of tuples (at least one: the LAB that starts the block), which you can identify by pointers to the first and last tuples in the block. Each node has no more than two exit arcs pointing at other nodes:
Note that although each node is followed by at most 2 successors, it may have any number of predecessors. You'll want to record the number of immediate predecessors in each node. Of course, the very first block is special -- it logically has infinitely many predecessors (anything at the operating system level could jump to it), despite the fact that the code you are processing might not have any arcs to it.
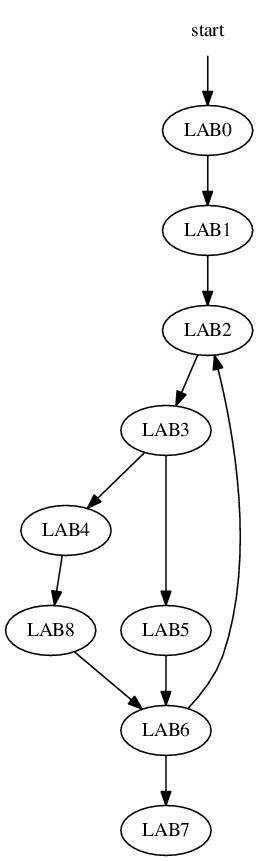
How do you output this graph? Well, I'm very fond of the GraphViz graph visualization software. There is an interface for C programs to actually produce GraphViz rendings, but all I'm asking is that your program output the graph as ASCII text using the DOT language. Here's a really simple example of how that works. The DOT file:
digraph {
start [shape=none];
start -> LAB0;
LAB0 -> LAB1;
LAB1 -> LAB2;
LAB2 -> LAB3;
LAB3 -> LAB4;
LAB3 -> LAB5;
LAB4 -> LAB8;
LAB5 -> LAB6;
LAB6 -> LAB2;
LAB6 -> LAB7;
LAB8 -> LAB6;
}
when run through the command dot -Tps <dig.dot >dig.ps generates a postscript file that looks like:
You might have noticed that the dot rendering cleverly moved the LAB8 node into a more logical position as it drew the graph. Incidentally, I don't care what you name the nodes. Cool, eh?
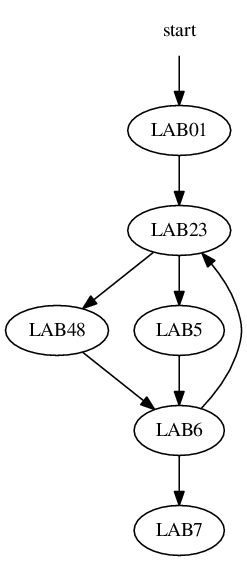
When you straighten the graph, you:
For example, the straightened version of the above graph is:
digraph {
start [shape=none];
start -> LAB01;
LAB01 -> LAB23;
LAB23 -> LAB48;
LAB23 -> LAB5;
LAB48 -> LAB6;
LAB5 -> LAB6;
LAB6 -> LAB23;
LAB6 -> LAB7;
}
and generates the graphic output:
Easy, right?
Ok, it's not quite that easy. You knew there had to be a catch. Here it is:
I actually want you to combine the blocks and spit out optimized code for them just like in the previous asignment.
To be very precise, the graph DOT specifications should be followed by text output of the optimized code in the same notation used for the previous project. Note that this is not as complex as doing linear nested region analysis, but it is capable of making some pretty significant code improvements.
There are two basic approaches to optimizing the straightened code. Both are based in walking through the control flow graph to order and output code. Your walk should begin with the start node and visit all previously-unvisited reachable nodes... which should suggest a work list or a recursive walk testing a "visited" flag. The two basic approaches to optimizing are:
This last part will only count for 20% of this project. Why? So that you can still get an "A" on the project by generating a correctly straightned graph and having implementor's notes that explain your final code output doesn't work.
The recommended due date for this assignment is before class, April 11, 2017. The actual submission will not close until before class Tuesday, April, 18 2017 -- but be warned that the next project may be assigned before then. You may submit as many times as you wish, but only the last submission that you make before the final deadline will be counted toward your course grade.
Note that you can ensure that you get at least half credit for this project by simply submitting a tar of an "implementor's notes" document explaining that your project doesn't work because you have not done it yet. Given that, perhaps you should start by immediately making and submitting your implementor's notes document? (I would!)
For each project, you will be submitting a tarball (i.e., a file with the name ending in .tar or .tgz) that contains all things relevant to your work on the project. Minimally, each project tarball includes the source code for the project and a semi-formal "implementors notes" document as a PDF named notes.pdf. It also may include test cases, sample output, a make file, etc., but should not include any files that are built by your Makefile (e.g., no binary executables). Make it very clear in your implementor's notes exactly what each file is and, if you're an undergrad, which project you did: VLIW or pipeline.
Submit your tarball below. The file can be either an ordinary .tar file created using tar cvf file.tar yourprojectfiles or a compressed .tgz file file created using tar zcvf file.tgz yourprojectfiles. Be careful about using * as a shorthand in listing yourprojectfiles on the command line, because if the output tar file is listed in the expansion, the result can be an infinite file (which is not ok).