-
For this question, check all that apply.
Consider the following two MIPS subset implementations:

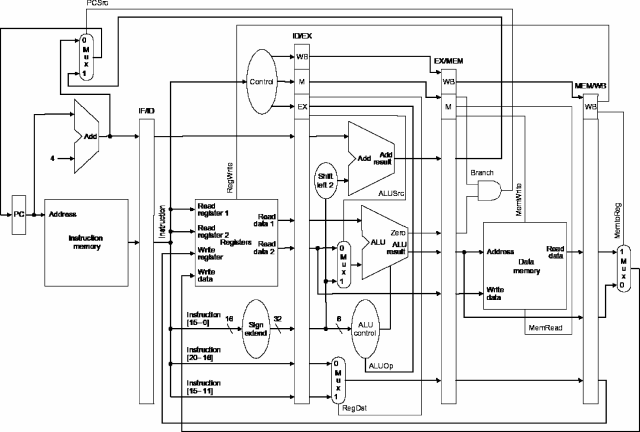
Which of the following four statements about how
pipelining changes the architecture is true?
The Data Memory module could be the same circuit in both
implementations
The Instruction Memory module could be the same circuit in both
implementations
The ALU used for operations like add and xor
could be the same circuit in both implementations
The control signals used to implement each instruction
could be the same in both implementations
The whole point of the single cycle design is that you
use it as the basis for the pipelined implementation!
-
Pipelined designs generally achieve higher performance
than similar single-cycle designs by allowing a higher clock
rate, but the clock rate with a 5-stage pipeline is generally
somewhat less than 5X the speed of the single-stage design it
was derived from (e.g., compare the two MIPs implementations
given in question 1). Give one reason why the clock rate is
less than 5X.
-
The first time a modern processor executes a particular branch
instruction, it must compute the target address by adding the
offset encoded within the branch instruction to the PC value.
However, if the same instruction is executed again soon enough,
the processor does not have to recompute the target address.
Which hardware structure implements this feature?
BHB
BTB
TLB
Instruction Cache
BHB is Branch History Buffer used for branch prediction;
BTB is Branch Target Buffer;
TLB is Translation Lookaside Buffer used to map logical in physical addresses
-
Consider executing each of the following code sequences on the
pipelined MIPS implementation given below
(which does not incorporate value forwarding):
Incidentally, both code sequences produce the same final
results. Which of the following statements best describes
the execution times you would expect to observe?
(A) addi $t1,$t0,4
lw $t2,0($t0)
xor $t2,$t2,$t3
(B) lw $t2,0($t0)
addi $t1,$t0,4
xor $t2,$t2,$t3
(A) would be faster than (B)
(B) would be faster than (A)
(A) would take the same number of clock cycles as (B)
The only true dependence is xor depends on lw result,
which would require 3 clock cycles between them.
That means there is a 3-stage bubble in (A), but only 2-stage on (B).
-
Consider executing each of the following code sequences on the
pipelined MIPS implementation given below:
Also consider executing them on this design with value
forwarding logic and datapaths added. Which of the
following statements best describes how the forwarding
logic would alter the execution times?
(A) lw $t1,4($t0)
sw $t1,16($t2)
beq $t1,$t3,lab
(B) lw $t1,4($t0)
sw $t2,16($t3)
beq $t0,$t3,lab
Neither (A) nor (B) is affected by
forwarding
(A) is not affected, (B)
would be faster using forwarding
(A) would be faster using forwarding, (B) is not affected
Both (A) and (B) would be faster using
forwarding
The execution time
improvements due to forwarding depend on the values in the registers, not on
the instructions being executed; thus, it is impossible to say how execution
times for (A) and (B) are affected
There is a true dependence between lw and both the sw
and beq in (A); although (B) has an
anti-dependence on $t0, it has no true dependences that could cause bubbles.
Forwarding simply reduces the size of the bubble caused by a true dependence.
-
For this question, check all that apply.
The Intel Pentium 4 has gone through several revisions; the
following diagram shows the internals of the version known as
Prescott. According to the diagram, which of the following
techniques is used in this design?
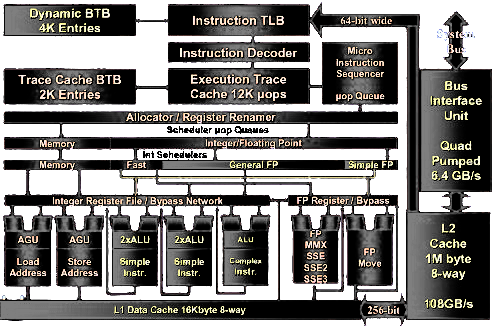
Out-of-order execution
Direct-mapped data cache
Separate L2 caches for code and data
Superscalar execution of integer arithmetic
8-way means set associative with a set size of 8 lines.
-
Suppose that a simple system has a single cache with an access
time of 3 clock cycles. Cache misses are satisfied with an
average memory latency of 200 clock cycles. Assuming a cache
hit ratio of 0.9 (90%), how long does the average reference
take? Don't worry about the numerical value of the answer;
just show the formula that would give the answer.
-
Given the declarations int a[N][N]; int i, j;, a C
compiler would allocate N*N words in memory for
a such that a[i][j] is (i*N)+j words
after the memory location that holds a[0][0]. Given
that N is large, which of the following two loop nests
is likely to execute faster and why:
(1) for (i=0; i<N; ++i) for (j=0; j<N; ++j) a[i][j] = 0;
(2) for (j=0; j<N; ++j) for (i=0; i<N; ++i) a[i][j] = 0;
The
general rule here is that you want to maximize spatial locality, which means
you don't want things you aren't accessing between things you are touching.
This affects both program access order (as here) and choice of data layout.
Separate arrays vs. array of structs layouts should really be based on what is
accessed together. E.g., if you have x, y, z coordinates
for each of N points, but your code only looks at x, y in the same loop and z in a
different loop, store x, y data together and z separate:
struct { int x, y; } xy[N]; int z[N];
Note that you can even figure-out approximately how many cache
and TLB misses a piece of code will have -- the cache line size is typically 32B and a
TLB entry covers a 4KB page.
-
For this question, check all that apply.
In a typical modern PC processor, which of the
following four memory subsystems typically is found
on the processor chip?
TLB
L2 Cache
Registers
L1 Data Cache
Lower-level caches might still be off chip,
and main memory usually is off chip, but
the top portion of the memory hierarchy has been
on chip ever since transistor count allowed it
-
For this question, check all that apply.
Which of the following four statements about the memory
hierarchy are true?
Larger cache line sizes take better advantage of Spatial
Locality
Modern processors often have separate caches for instructions
and data
Spatial Locality refers to an object being likely to be
referenced again soon after being referenced once
For comparable cache size, a direct mapped cache is harder to
build (more complex logic) than set associative cache
Temporal locality is repeated access to the same word;
spatial is touching nearby things -- which is obviously
helped by grabbing a larger line when there's a miss.
Nearly every pipelined processor has separate L1 instruction
and L1 data caches because a single cache would tend to
be a structural hazzard -- accessed simultaneously in two
pipe stages.
Associativity gives hardware a choice
of which line to replace, which requires some hardware to
implement a replacement policy such as LRU -- direct mapped
is simpler because the hardware has no choice.