Consider executing each of the following code sequences on the
pipelined MIPS implementation given below
(which does not incorporate value forwarding):
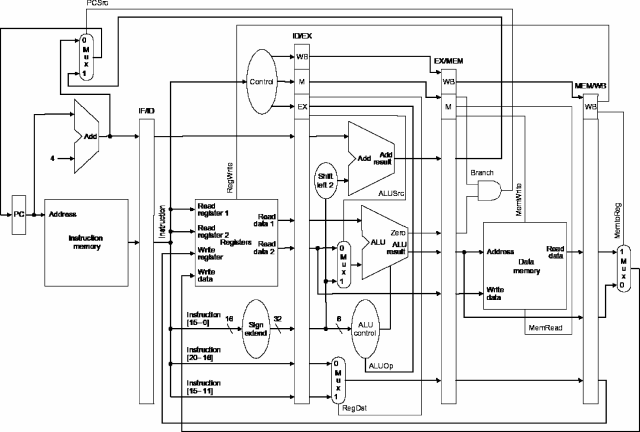
Incidentally, both code sequences produce the same final
results. Which of the following statements best describes
the execution times you would expect to observe?
(A) addi $t1,$t0,4
lw $t2,0($t0)
xor $t2,$t2,$t3
(B) lw $t2,0($t0)
addi $t1,$t0,4
xor $t2,$t2,$t3
(A) would be faster than (B)
(B) would be faster than (A)
(A) would take the same number of clock cycles as (B)