Hardware Barrier Synchronization
For A Cluster Of Personal Computers+
T. Muhammad
MS Thesis Defense
School of Electrical Engineering
Purdue University
West Lafayette, IN 47907-1285
February 2, 1995
 (
4K .ps.Z )
(
4K .ps.Z )
+ This work was supported in part by the Office of Naval
Research (ONR) under grant number N00014-91-J-4013.
-
Treats a group of machines as a parallel machine
-
Workstations and PCs offer high performance, low cost
-
Networks increasing bandwidth, decreasing cost:
-
Politically correct (use things you already have)
-
Fine-grain parallelism needs low latency
-
Networks designed for bandwidth, not latency
-
Minimum latency of 1,000-5,000 microseconds
-
Need efficient barrier synchronization
-
Data parallelism and SPMD workforce models
-
SIMD and VLIW emulation
-
Megjou Lin et al. used an ATM cluster of 4 Suns to compare
performance of AAL5, API, PVM, and BSD stream sockets
Latency was 800µs -- 3,000µs
-
Chengchang Huang used an ATM cluster of 11 SPARC-10 with PVM
and AAL5
Latency was >1,000µs
-
NAS (NASA Ames Lab) tested various clusters with PVM
Latency was >700µs for IBM Allnode,
2,000µs -- 3,000µs for FDDI and Ethernet
-
Thekkath proposed a "remote memory" model using 4 DEC R3000
machines with ATM hardware
Latency as low as 30µs to 45µs?
-
Signal present at barrier
-
Wait for all participating processors
-
When all have arrived, resume execution
-
Software/messaging implementations are inefficient
-
First used by Harry Jordon in FEM, 1978
Priority chain hardware
-
Burroughs FMP
AND tree hardware, tree-node partitioning
-
Fuzzy barrier by Gupta
Delayed firing, overly complex hardware
-
Thinking Machines CM-5
Control network works like AND tree
-
Cray T3D
like FMP, but 8 bits wide
-
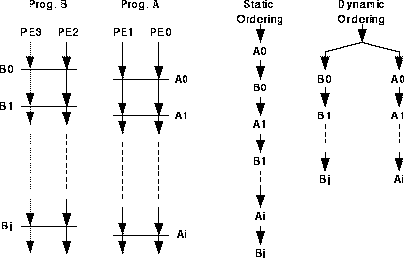
Everybody built static barrier hardware
-
Static: one barrier stream
-
Dynamic: multiple independent barrier streams
(arbitrary partitioning of the machine)
 (
11K .ps.Z )
(
11K .ps.Z )
-
Any set of processors can be a barrier group
-
A group can be represented by a bit mask
-
Concept of arbitrary masks came from H. Dietz and T.
Schwederski at Purdue in 1987 as outgrowth of PASM SIMD
enable logic
-
Runtime partitioning method was not specified
-
1987
-
Basic Concepts of barrier MIMD
Compiler technology based on VLIW scheduling
-
1990
-
SBM using a "barrier processor" and mask queue
DBM using a "barrier processor" and associative mask
memory
Compiler technology based on timing analysis
-
1993
-
Improved DBM design with runtime partitioning support
-
1987
-
PASM implements SBM
-
1987
-
CARP (Compiler-oriented Architecture Research at Purdue)
Machine design: barrier MIMD using custom VLSI
-
1993
-
CARDBoard (Compiler-oriented Architecture Research
Demonstration Board)
System design: DBM using RISC microprocessors in a
custom board
-
1994
-
PAPERS (Purdue's Adapter for Parallel Execution and Rapid
Synchronization)
Cluster design: DBM using PCs and an external adapter
PAPERS0 implements improved DBM
-
Initially, intended to be an SBM
-
Simple global AND hardware
-
Extended load processor interface (like PASM)
-
Load address is decoded as barrier request
-
Load does not complete (logic inserts memory wait states)
until all processors are present
-
Implement "distributed" DBM hardware
-
Replicate OR-AND trees for each processor
-
Uses barrier masks stored locally by each processor
-
Extended load interface, but some address bits are decoded
as the barrier mask
 (
9K .ps.Z )
(
9K .ps.Z )
-
Runtime partitioning seemed desirable, but:
-
Must use separate data network to agree on new masks
-
Once partitioned, subgroups can't recombine
 (
8K .ps.Z )
(
8K .ps.Z )
-
Invented in October 1993
-
Adds to basic CARD DBM design:
-
Load address includes a one-bit flag value
-
Load returns a bit vector gathering the flag bits from all
processors
-
Every processor send its n-bit mask, each bit to the
corresponding processor
-
Partitioning doesn't need a separate data network
-
Recombining subgroups works
-
Wiring complexity goes from O(n) to O(n2)
 (
5K .ps.Z )
(
5K .ps.Z )
-
CARD project was delayed waiting for:
-
Microprocessors (first TMS320C30, then AMD29050 and
PowerPC601)
-
Xilinx glue logic design support tools
-
More design and construction experience
(no new hardware since 1987)
-
Improved DBM is very new --
we needed to test the design concepts
-
Use standard PCs as processing elements
-
Barrier unit is an external box connected to all PCs
 (
8K .ps.Z )
(
8K .ps.Z )
-
Use a custom interface card:
ISA, EISA, VESA, or PCI
-
Use a standard interface:
RS232, Parallel Printer Port, SCSI
-
Why we use the parallel printer port:
-
Number of usable signal lines
-
Simplicity of the hardware interface (TTL logic levels)
-
Relatively easy direct software access to the port
(very low latency)
-
Load interface cannot be implemented!
-
Printer port is mapped as an I/O device
-
Signals controlled by data bus read/write of I/O registers
-
Requires a minimum of two port accesses, at 1-5 microseconds
each
-
Running Linux (UNIX) on each processor blurs timing
-
Must use a memory element to ensure barrier GO signals are
not missed
-
Must distinguish between barrier request and barrier seen
 (
14K .ps.Z )
(
14K .ps.Z )
-
Needed to achieve initial synchronization
(known barrier state)
-
To recover from program errors
(including mask errors)
-
To use PAPERS for parallel OS functions
(without an additional network)
-
Simplest form is a global OR of IRQ from all PEs
-
PAPERS is partitionable, so interrupt should affect only the
specified partition and use AND-OR tree implementation
-
Reciever determines which processors can interrupt it
-
Requestor determines the group it will interrupt
 (
9K .ps.Z )
(
9K .ps.Z )
 (
9K .ps.Z )
(
9K .ps.Z )
 ( 12K .ps.Z )
( 12K .ps.Z )
-
Connects four PCs or workstations using improved DBM
-
For each processor:
-
One PLA implements barrier and interrupt logic
-
Data bits are buffered through TTL drivers
-
10 status LED display
-
Connection to the PC is made via a centronics printer cable
-
PLAs have common internal logic but different connections
between chips
 ( 13K .ps.Z )
( 13K .ps.Z )
 ( 9K .ps.Z )
( 9K .ps.Z )
-
It really works... with speed limited by slow ports
-
Low latency barrier synchronization
-
Low latency data communication
 ( 4K .ps.Z )
( 4K .ps.Z )
-
Fine-grain MIMD and SPMD with barriers
-
Fine-grain SIMD emulation
-
Fine-grain VLIW emulation
-
What do we mean by fine grain?
-
Minimum PAPERS0 communication takes 11µs on a 4 MFLOPS
machine
-
PAPERS0 grain size is about 44 FLOPS
-
Newer PAPERS units are at 2.5µs, or about 10 FLOPS
-
The improved DBM needs one-bit multi-broadcast, thus,
PAPERS0 can implement any aggregate communication function
without routing conflicts
-
Later versions of PAPERS expand this:
-
ANY and ALL tests
-
Multibit global OR, multibroadcast
-
Voting operations
-
Voting operations allow PAPERS to be used for scheduling
access to other resources
(e.g., a high-bandwidth network)
-
"Standard" printer port?
-
Driving TTL levels through lousy 10' cables and too many
connectors...
-
Can go from 4 or 5 port accesses/op to just 2
-
Fancy LED displays help debugging, but...
-
A cheap AC adaptor + 7805 works as well as a $50 power
supply
-
Wire wrap creates debugging problems
-
PAPERS an effective way to interconnect computers in a
cluster
-
PAPERS0 is the first system to make a PC/workstation cluster
capable of fine-grain mixed-mode parallel execution
-
Experiments with PAPERS0 have thus far spawned 5 generations
of other PAPERS prototypes, including a publically
demonstrated and released simplified version (TTL_PAPERS)
-
Implementation for larger clusters:
-
TTL_PAPERS SBM design for 32 processors
-
Full DBM PAPERS design for 16 processors
-
Plans to scale to 128 or 256 processors within this year
-
Design of a minimal custom interface board that will allow
the Load interface to be used with existing PAPERS designs
-
A high-performance PCI-interface PAPERS... hopefully
leading to CARDBoard and perhaps even a CARP machine
-
Use of the unidirectional parallel printer port for parallel
processing
-
Simplified construction of the prototypes
-
Portably yields good performance
-
I played a leading role in designing, implementing, and
debugging the first DBM ever built
-
My thesis explains how and why the barrier mechanism evolved
into the improved DBM
-
PAPERS works very well, and has been very well recieved by
the parallel processing research community:
-
Equipment loans/donations from TI, IBM, DEC, etc.
-
20'x20' research exhibit at IEEE/ACM Supercomputing '94
-
Publications
-
H. G. Dietz, T. M. Chung, T. I. Mattox, and T. Muhammad,
"Purdue's Adapter for Parallel Execution and Rapid
Synchronization: The TTL_PAPERS Design," submitted to
International Conference on Parallel Processing, August
1995.
-
H. G. Dietz, T. Muhammad, and T. I. Mattox, TTL
Implementation of Purdue's Adapter for Parallel Execution
and Rapid Synchronization, Purdue University School of
Electrical Engineering, December 1994.
-
H. G. Dietz, W. E. Cohen, T. Muhammad, and T. I. Mattox,
"Compiler Techniques For Fine-Grain Execution On Workstation
Clusters Using PAPERS," 7th Annual Workshop on Languages and
Compilers for Parallel Computing (also to appear as a book
chapter from Springer Verlag), pp. 3.1-3.15, Cornell
University, August 1994.
-
H. G. Dietz, T. Muhammad, J. B. Sponaugle, and T. Mattox,
PAPERS: Purdue's Adapter for Parallel Execution and Rapid
Synchronization, Purdue University School of Electrical
Engineering, Technical Report TR-EE 94-11, March 1994.
-
Clustering
-
-
Parallel Processing
-
-
Cluster Computing Latencies
-
-
Barrier Synchronization
-
-
Other Hardware Barriers
-
-
Static Vs. Dynamic Barriers
-
-
Barrier Groups (Masks)
-
-
Theoretical Barrier Work At Purdue
-
-
Experimental Barrier Work At Purdue
-
-
Original Concept Of CARD Barrier Hardware
-
-
Basic CARD DBM Design
-
-
Problems With The Basic CARD DBM Design
-
-
Improved CARD DBM Design
-
-
Improved CARD DBM Design
-
-
Why PAPERS?
-
-
Generic PAPERS Cluster Concept
-
-
What Hardware Interface?
-
-
Problems
-
-
PAPERS Barrier Logic (For One Processor)
-
-
Parallel Interrupts?
-
-
Interrupt Architecture For PAPERS
-
-
The Two Interrupt Mask Alternatives
-
-
Generic PAPERS Block Diagram
-
-
PAPERS0 Implementation
-
-
PAPERS0 Logic Schematic
-
-
PAPERS0 Display Schematic
-
-
Performance Of PAPERS0
-
-
What Can A PAPERS Cluster Do?
-
-
PAPERS As A Communication Network
-
-
Lessons From PAPERS0
-
-
Conclusion
-
-
Future Work
-
-
Significance Of My Contribution
-
-
Publications From This Work
-
-
Hypertext Index
-